~{→看不见LaTex格式的Dalao们请刷新本页Thanks♪(・ω・)ノ←}~
一、启发式合并的算法原理
我们常用路径压缩的方法来减少内存消耗,但是过程中会损失掉很多的数据信息,如果用冰茶几来维护又会消耗很多时间,这时候我们需要用到启发式合并。
我们用并查集时,很多时间都浪费在了$getfa()$这个函数上面,我们考虑对$getfa()$进行优化。启发式合并使它的时间复杂度能尽可能控制在$O(logn)$左右。
并查集是树型的数据结构,有深度这一概念,如果我们把深度大的树的根节点接在深度小的树上,那么深度反而会增大,时间消耗就会更多。
那启发式合并就是把小的树的根节点接在大的树上,那么深度就是$max(h_小+1,h_大)$,这就是启发式合并的原理。
二、我们借图来理解一下。
一开始有两棵树高度分别为3和5
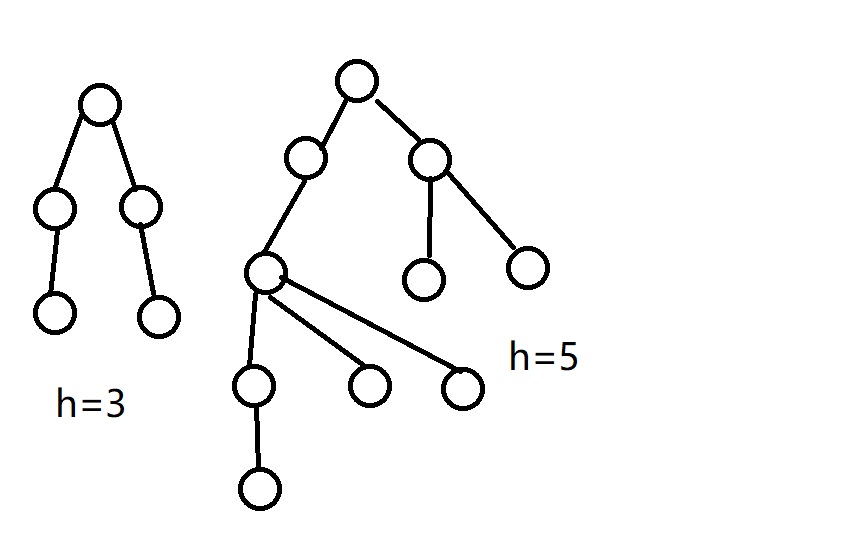
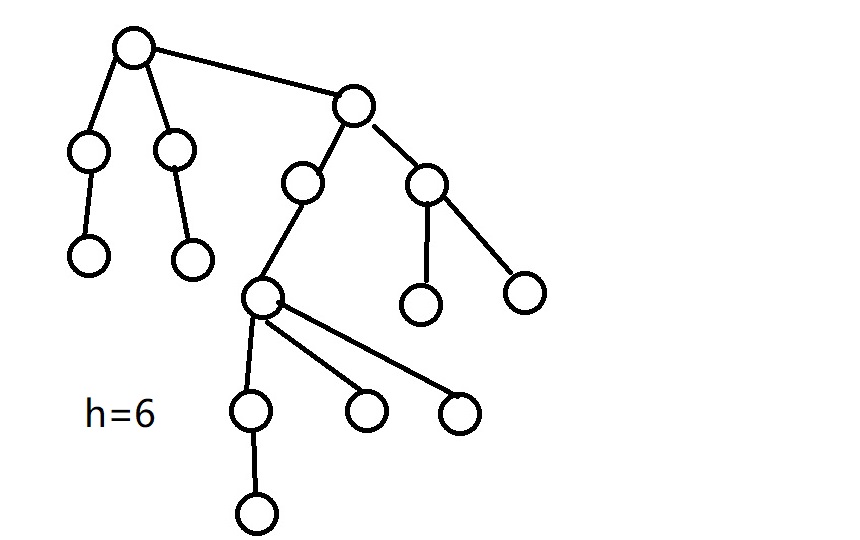
如果是并查集的$getfa()$操作,那么树会变成这样
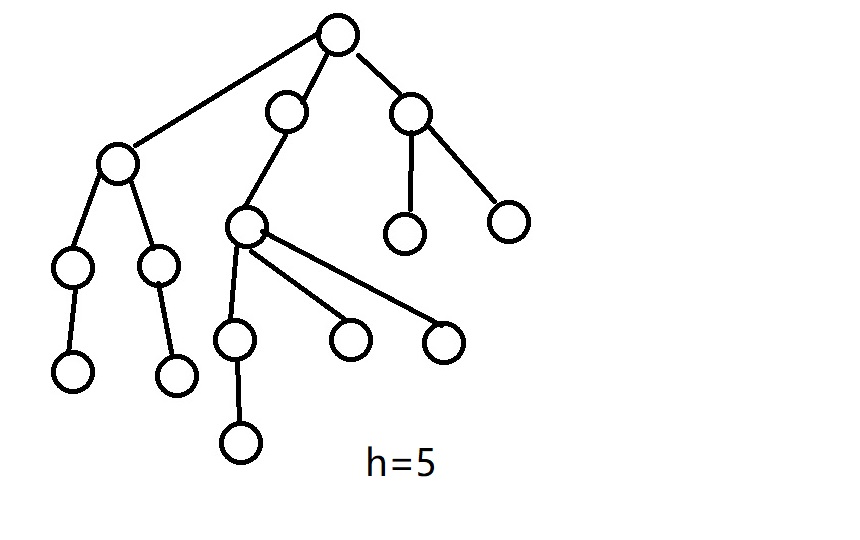
而进行了启发式合并的树是这样的
三、Code
1 | void qfs_union(int x,int y) |
1 | int find(x) |