~{→看不见LaTex格式的Dalao们请刷新本页Thanks♪(・ω・)ノ←}~
我对二分图简直自闭,决定再次学习一波,唉。
一、二分图的定义
简单的说,如果图中的点可以被分为两组,并且所有的边的两端不在同一组内,也就是说都连通两个组,那么这就是一个二分图。
二分图还有另一个定义,如果把一个图的顶点划分为两个不相交集,使每一条边分别连接两集中的顶点,那么这就是一个二分图。
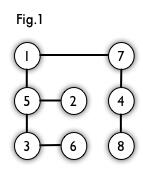
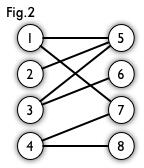
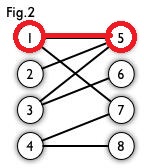
Fig1是一个二分图,看起来不方便,就画成Fig2。
二、匹配的定义
- 简单地说,就是一个边集,且满足其中任意两边都没有公共顶点。
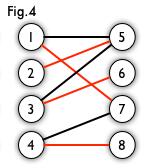
如图,Fig3、Fig4是Fig2 的匹配:
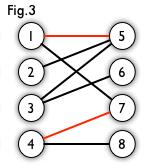
匹配中还有一些定义:匹配点,匹配边,未匹配点,非匹配边。比如Fig3中的1,4,5,7是匹配点,1-5,4-7是匹配边。
最大匹配:一个图的所有匹配中,所含匹配边最多的匹配,称为该图的最大匹配。Fig4是一个最大匹配。
- 完美匹配:如果一个匹配内,所有的点都是匹配点,那么这个匹配就是一个完美匹配,显然有,完美匹配一定是最大匹配。但是并不是所有的图都存在完美匹配。
三、另一些定义(匈牙利算法)
交替路:从一个未匹配点出发,依次经过非匹配边,匹配边,非匹配边,匹配边……如此形成的路径叫交替路。
增广路:从一个未匹配点出发,走交替路,如果途径另一个未匹配点,但不能算出发点,那么这条路叫做增广路。如图,Fig5中的增广路为Fig6:
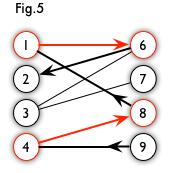
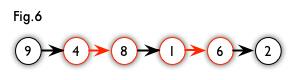
增广路有一个特点:非匹配边一定比匹配边多一条。
- → 由此,只要把增广路中的匹配边和非匹配边身份交换即可。由于中间的匹配节点不存在其他相连的匹配边,所以这样做不会破坏匹配的性质。交换后,图中的匹配边数比原来多1条,其实如果交替路以非匹配点结束,那么该交替路就是一条增广路。
四、匈牙利算法
1、基本思想:
通过寻找增广路,把增广路的匹配边和非匹配边身份交换,多出一条匹配边,直到不能找到增广路为止。
Code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
using namespace std;
int nx,ny;//nx表示二分图左边顶点的个数,ny表示二分图右边顶点的个数
int m;//m代表边的条数
int cx[MAXN],cy[MAXN];//如果有cx[i]=j,则必有cy[j]=i,说明i点和j点能够匹配
int x,y;//x点到y点有边
int e[MAXN][MAXN];//邻接矩阵
int visited[MAXN];//标记数组,标记的永远是二分图右边的顶点
int ret;//最后结果
int point(int u)//这个函数的作用是寻找增广路和更新cx,xy数组,如果找到了增广路,函数返回1,找不到,函数返回0。
{
for(int v=1;v<=ny;v++)//依次遍历右边的所有顶点
{
if(e[u][v]&&!visited[v])//条件一:左边的u顶点和右边的v顶点有连通边,条件二:右边的v顶点在没有被访问过,这两个条件必须同时满足
{
visited[v]=1;//将v顶点标记为访问过的
if(cy[v]==-1||point(cy[v]))//条件一:右边的v顶点没有左边对应的匹配的点,条件二:以v顶点在左边的匹配点为起点能够找到一条增广路(如果能够到达条件二,说明v顶点在左边一定有对应的匹配点)。
{
cx[u]=v;//更新cx,cy数组
cy[v]=u;
return 1;
}
}
}
return 0;//如果程序到达了这里,说明对右边所有的顶点都访问完了,没有满足条件的。
}
int main()
{
while (cin>>m>>nx>>ny)
{
memset(cx,-1,sizeof(cx));//初始化cx,cy数组的值为-1
memset(cy,-1,sizeof(cy));
memset(e,0,sizeof(e));//初始化邻接矩阵
ret=0;
while (m--)//输入边的信息和更新邻接矩阵
{
cin>>x>>y;
e[x][y]=1;
}
for(int i=1;i<=nx;i++)//对二分图左边的所有顶点进行遍历
{
if(cx[i]==-1)//如果左边的i顶点还没有匹配的点,就对i顶点进行匹配
{
memset(visited,0,sizeof(visited));//每次进行point时,都要对visited数组进行初始化
ret+=point(i);//point函数传入的参数永远是二分图左边的点
}
}
cout<<ret<<endl;
}
}
//%%%%%%%%%%%%
//来自csdn--栾琪
//%%%%%%%%%%%%2、分析
我们拿出Fig2来分析一波:
分析一下$point()$函数的运行过程,第一次以$1$顶点为起点进入$point(1)$函数,然后5号顶点满足条件,更新$cx[1],cy[5]$,返回$1$。此时$1→5$这条边为匹配边,$1$号,$5$号顶点为匹配顶点。
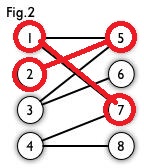
然后以$2$顶点为其实点进入$point(1)$函数,然后访问到$5$号节点,然后以$5$号节点的匹配点$1$号节点为起始点再次进入$point(2)$函数,找到了$7$号点,这时说明找到了增广路,然后更新$cx[1],cy[7]$,然后返回$1$,更新$cx[2],cy[5]$,返回$1$,函数结束。
然后以$3$号顶点为起始点进入$point(1)$函数,然后访问到$5$号节点,然后以$5$号节点的匹配点$2$号节点为起始点再次进入$point(2)$函数,找不到点了,返回$0$,到达$point(1)$函数,继续访问其他的节点。然后访问到$6$号顶点,满足条件,更新$cx[3],cy[6]$,返回$1$,函数结束。
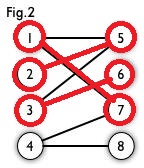
然后以$4$号顶点为起始点进入$point(1)$函数,然后访问到$7$号节点,然后以$7$号节点的匹配点$1$号节点为起始点再次进入$point(2)$函数,然后找到$5$号节点,然后以$5$号节点的匹配点$2$号节点为起始点再次进入$point(3)$函数,找不到点了,返回$0$,到达$point(2)$函数,继续访问其他的节点,没有点了,返回$0$,到达$point(1)$函数,继续访问其他的节点,到达了$8$号节点,满足,然后更新$cx[4],cy[8]$,返回$1$,函数结束。
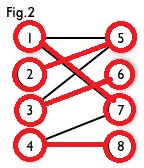
这样我们就找到了所有的匹配边。
五、KM算法
见blog:
https://www.cnblogs.com/wenruo/p/5264235.html
https://www.cnblogs.com/logosG/p/logos.html?tdsourcetag=s_pcqq_aiomsg
Code
1 |
|
六、Gale-Shapley—-婚姻匹配算法算法
见blog:
https://blog.csdn.net/Air_hjj/article/details/70828937
https://blog.csdn.net/lc_miao/article/details/78116064
Code
1 |
|
什么?你说为什么我后面都没了?都只挂了一个(不不不,其实是两个)博客地址呢?
那还用说!我不会啊_(¦3」∠)_